

Topic modeling is an unsupervised learning procedure similar to clustering used in exploratory analysis of text. It classifies text in different sets known as topics. In this post I give a brief introduction to Topic Modeling, introduce the classic LDA method and explain why Transformer based methods (such as my library transformertopic) are much more usable in practice. To see a concrete example, check out this post where I apply the method to COVID news and in particular the last section where I show with a concrete example why LDA topics are less usable.
Old-school NLP: LDA
Topic Modeling has been around since the late ’90s. Probably the most impactful paper in the field is from Blei et al. in 2002 [1], in which the authors introduced the so-called Latent Dirichlet Allocation (LDA). The method, of which nowadays countless variants exist, is a sophisticated Bayesian framework in which topics are defined as probability distributions over a dictionary of words and each sentence (or document) is modeled as a probability distribution over topics (i.e. an ell_1 — normalized linear combination of topics). These distribtutions are learned via Bayesian inference. See also the wikipedia page for some more details.
From a very practical standpoint (which is the perspective of this whole post) topics are de-facto identified with their word cloud representation, where the larger words (graphically speaking) should be more representative of the topic (semantically speaking). In LDA-world the natural way to do it is by assigning the probability of a word in a topic to its graphical size in the word cloud.
Evaluation of models
Though attempts have been made to find quantitative measures of quality of the generated topics (see [2] for a review and comparison), in practice the only measure that matters is: “How good are the word clouds?”. Ideally we would like for each word cloud to be semantically very different from each other and be clearly representable by one or two words (that is after all how we commonly think of topics), but it often happens that different topics have a large overlap in their word clouds and these consist mostly of very common words or words that seem to have no clear semantic relationship.
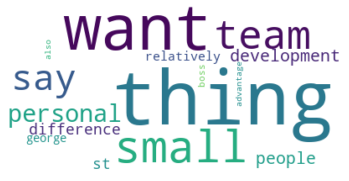
Example of a bad word cloud. What type of texts would you expect to be classified as the corresponding topic?W
Why LDA performs poorly
I think the underlying reason why LDA often performs poorly in this sense is because it is based on the bag-of-words (BOW) model. In BOW an ordered list is created with all the words in a language, and each word is then encoded as a one-hot vector: 0 everywhere except for the index the word has in the list, where it is 1. A sentence (or a paragraph, a document) is then simply represented as the sum of the one-hot vectors of the words in it. These vectors are the data points we feed into LDA, and thus LDA knows only about word frequency and nothing about semantics: the sentences “Who are you” and “You are who” have identical representations in BOW.
Modern NLP: transformers and sentence embeddings
Since BERT [3] came out in 2018 however NLP has changed forever, and BOW will soon have no other practical purpose than being used in introductory NLP texts as a simple way to vectorize text. In fact BERT, which is based on the Transformer architecture and achieved SOTA performance on 11 different NLP problems (at the time of publication), employs a clever scheme to learn vector representations of sentences known as sentence embeddings.
Sentence embeddings are much better vector representations of sentences than those obtained with BOW, because they approximate semantic relationships between — sentences with similar meaning are close together in this space. The authors achieve this by taking a large corpus of English texts and training BERT on two tasks: in the first they take as input sentences where a random word has been substituted with a special MASK symbol and try to predict the original word, in the second using a sentence in a paragraph as input they try to predict the next sentence. This is a semi-supervised procedure, called like this because labelled data can be automatically created starting from any corpus. If you know nothing about transformers but are interested in getting an idea of how they work, I suggest reading The Illustrated Transformer post by Jay Alammar.
transformertopic: how the method works
Since sentence embeddings have this nice property of approximating some sort of semantic space, where different regions of the space correspond to different areas of meaning, they can be clustered and the resulting clusters be called topics. In this post by Maarten Grootendorst he outlines a simple procedure based exactly on this idea; the steps are:
- compute sentence embeddings
- reduce dimensionality using UMAP
- cluster the vectors with HDBSCAN [4]
- use Tfidf to generate a word cloud from a cluster.
Step 2 is not strictly necessary but aids computation of step 3. I briefly experimented using PCA or PACMAP instead of UMAP, but the results were either too slow or worse quality. Regarding HDBSCAN, this makes a lot of sense because it has a bug (in the sense that because of this it is not really a clustering method by the classic definition) that is actually a feature: it does not force a point into a cluster if it is not close enough to the other points in it, i.e. outliers are left unclassified. This is a very useful feature because, in my experience, these outliers often correspond to low-content sentences, e.g. very short or using mostly very common words.
Unlike in LDA, we are not tied to the topic-as-a-probability-distribution paradigm, so in step 4 we can generate word clouds in a variety of ways — we just need a way to represent a cluster as a list of (word,rank) pairs, and use the rank for the graphical size of the word in the word cloud. The default Tfidf, which is obtained by dividing the frequency of a word in a cluster by the frequency of that word in the whole corpus, works quite well. I had some fun playing around with more fancy ways to rank words, like extracting keywords with Textrank [5] or Kmaxoids [6] (which wasn’t meant for this purpose), but in the end Tfidf gives the most consistent results.
While the author provides his own package, I wrote my own implementation of the method out of curiosity and to adopt a modular design that makes it easy to swap different methods for steps 2 and 4.
Farewell LDA
After having used LDA-based methods and this transformer-based procedure extensively at my previous job in the Future Engineering job at Fraunhofer IIS, I can confidently say this makes LDA obsolete. The quality of the topics is simply much higher and the word clouds almost always
- are easy to interpret
- represent a clear semantic cluster
- show topics you didn’t know were present.
To be fair, this last point is true about LDA as well (that is the whole point of exploratory analysis after all), but in my experience LDA produces a few gems (clear and insightful topics) amidst lots of noise (topics that are very ambigous and don’t feel cohese). With this transformer-based procedure the signal-to-noise ratio is much better.
Still not convinced? Check out the last section of my COVID news post where I show with a concrete example why LDA topics are less usable.
Conclusions and takeaways
Topic Modeling is “clustering for text” and can be used to discover what contents are present in a large corpus and track these over time. While in pre-BERT era many LDA variants were designed specifically for this task, with the great quality of sentence embeddings now available we can simply cluster these like any other type of data and obtain better, or at least more usable, results.
About me
I’m a Math PhD currently working in Blockchain Technical Intelligence. I also have skills in software and data engineering, I love sports and music! Get in contact and let’s have a chat — I’m always curious about meeting new people.
References
[6] Bauckhage, Christian, and Rafet Sifa. “k‑Maxoids Clustering.” LWA. 2015.