

In my previous post on transformers and topic modeling I introduced my library transformertopic. In this post I apply it to scraped news about COVID and discover a few fun facts:
- currently (November 2021) about one third of the sentences in COVID news is about vaccines
- sentences related to Trump had a sharp decline in frequency since December 2021
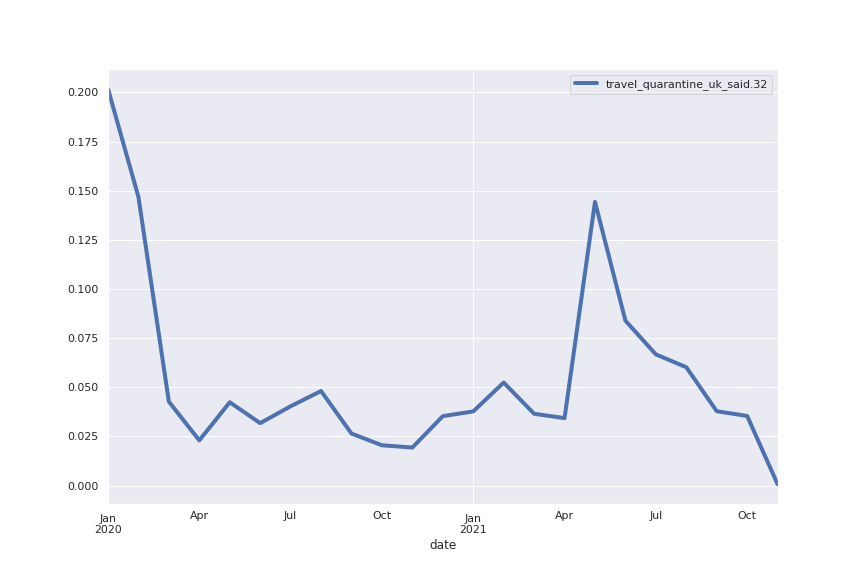
- concerns about travel regulations peaked in May 2021 and have been in sharp decline ever since
Data and methods
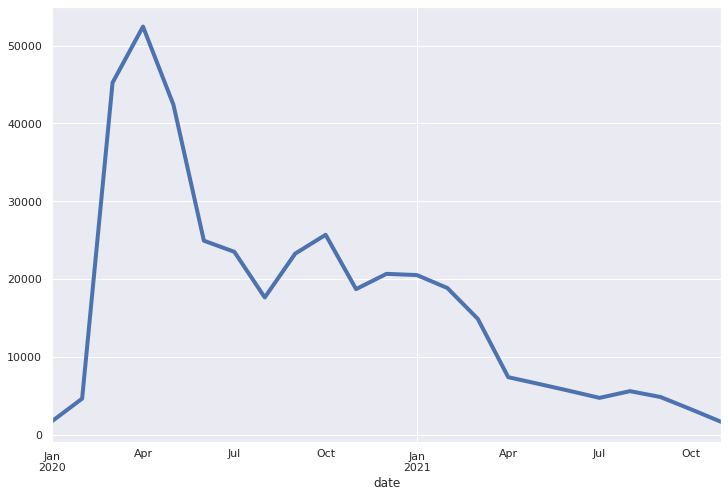
I scraped just shy of 12k articles that UK’s division of Huffington Post categorizes as related to COVID. I then split each article into sentences using spaCy’s Sentencizer and used the resulting list of approximately 395k sentences as corpus. The following is a plot of the corpus’ number of sentences per month:
I used my package (which you can install with pip install transformertopic) like this:
reducer = UmapEmbeddings(umapNNeighbors=13)
tt = TransformerTopic(dimensionReducer=reducer, hdbscanMinClusterSize=250)
tt.train(documentsDataFrame=df, dateColumn='datetime', textColumn='text', copyOtherColumns = True)Code language: PHP (php)where df is the pandas DataFrame with the data. In other words, I used the default paraphrase-MiniLM-L6-v2 embeddings for SentenceTransformer (you can find more embeddings here), the UMAP reducer with neighbors parameter set to 13 and set the HDBSCAN minimum cluster size to 250.
In this way I obtained 128 topics. This was actually my second attempt: at first I had set the minimum cluster size to 20 which resulted in some 4000 topics, a bit too much. This is a common occurrence: to get a reasonable number of topics usually some trial and error is required with the minimum cluster size and the neighbors parameter for UMAP (though I found 13 to be more often than not the magic number).
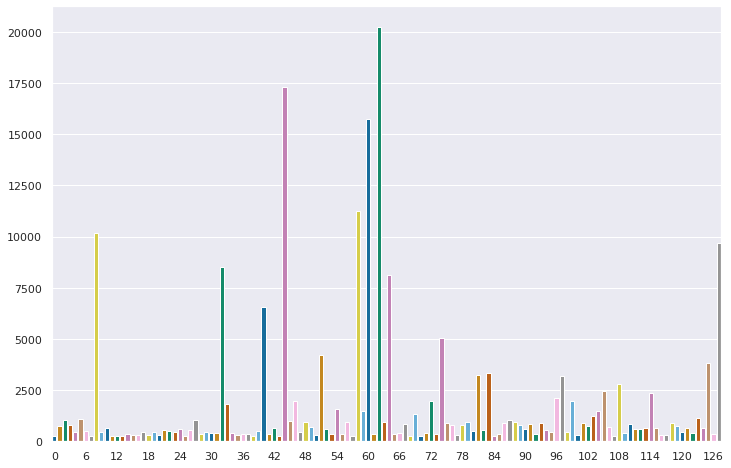
A histogram of the sizes of the obtained topics
Empirical study of the obtained COVID topics
Ok, so what do the topics look like? I will first present 8 of the largest topics, i.e. those which the greatest number of sentences are classified as, and subsequently I will present a selection of hand-picked topics that I found interesting.
For each of these 8 topics I am showing here their word clouds and their trends: the trend of a topic is simply a plot of the percentage of all sentences in a certain month that belong to the topic. I also show some example sentences (this is mostly to show that the method indeed works: each word cloud gives a clear idea of what content to expect in the sentences)
Topic 62: cases
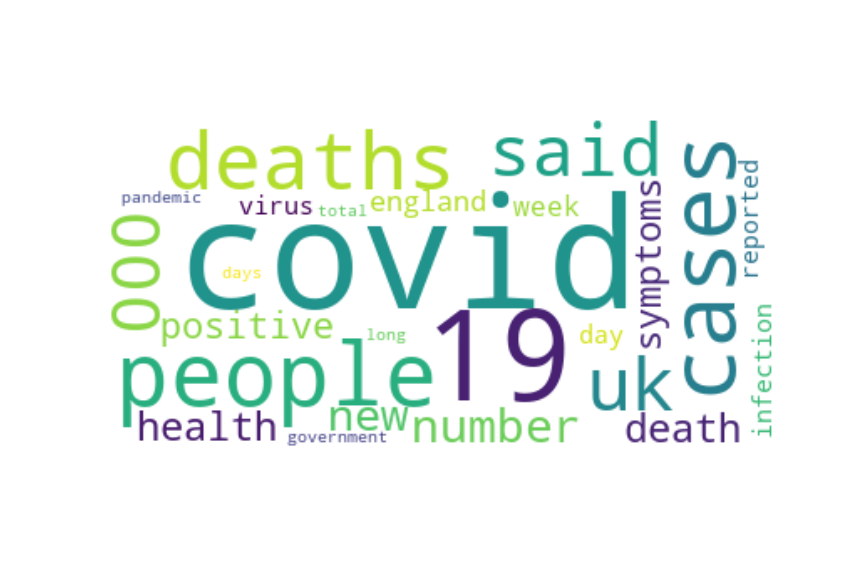
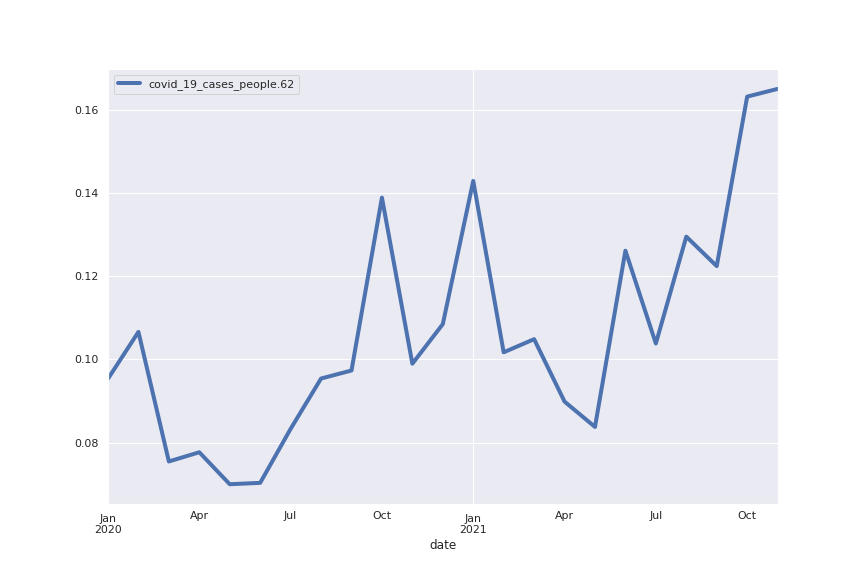
“The worry is that, as the epidemic now is increasing exponentially, we’ll see in a few months more deaths, but also a greater probability of infection jumping into the care homes,” he says, “and therefore higher death rates there as well.”
Following that there will be an “evidence-led” move down the tiers of restrictions once the UK has “broken the link” between cases and hospitalisations and deaths.
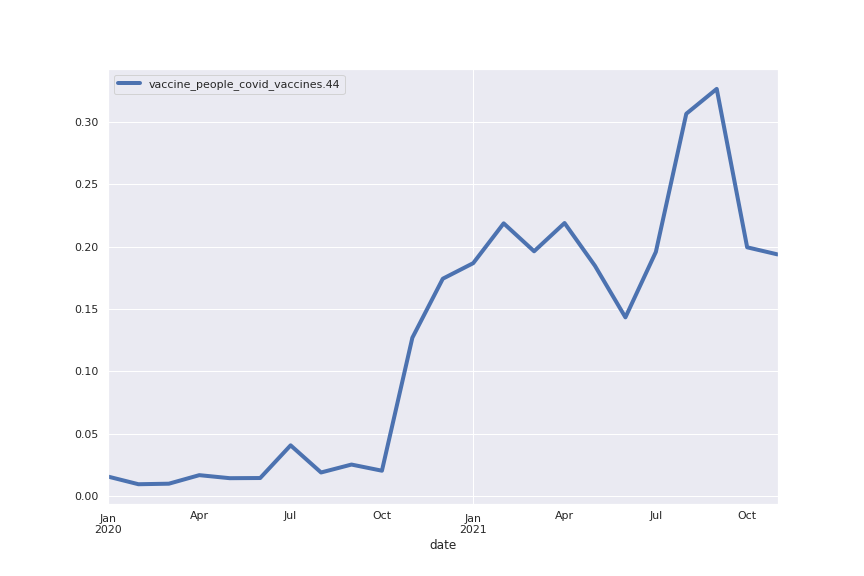
Topic 44: vaccine

“We have different ways of measuring the concentration of the vaccine and when it was apparent that a lower dose was used, we discussed this with the regulator, and agreed a plan to test both the lower dose/higher dose and higher dose/higher dose, allowing us to include both approaches in the phase III trial.
The health secretary repeatedly dodged questions about the reasons for the delay at the briefing, saying only that “vaccine supply is always lumpy and we regularly send out technical letters to the NHS”.
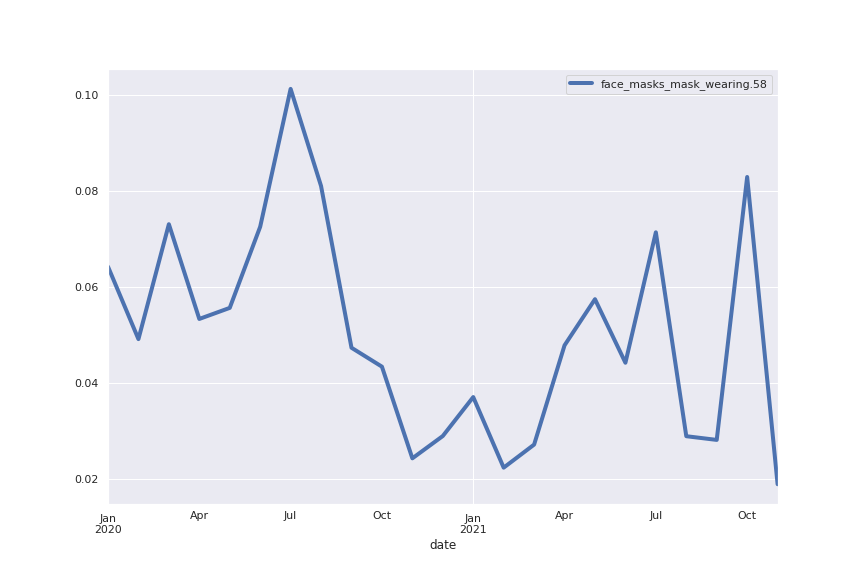
Topic 58: masks

“Both of these can be done by the use of face coverings.”
To get past this pandemic, we need to plug the holes by hand washing, social distancing, mask-wearing and disinfecting, Mushatt said.
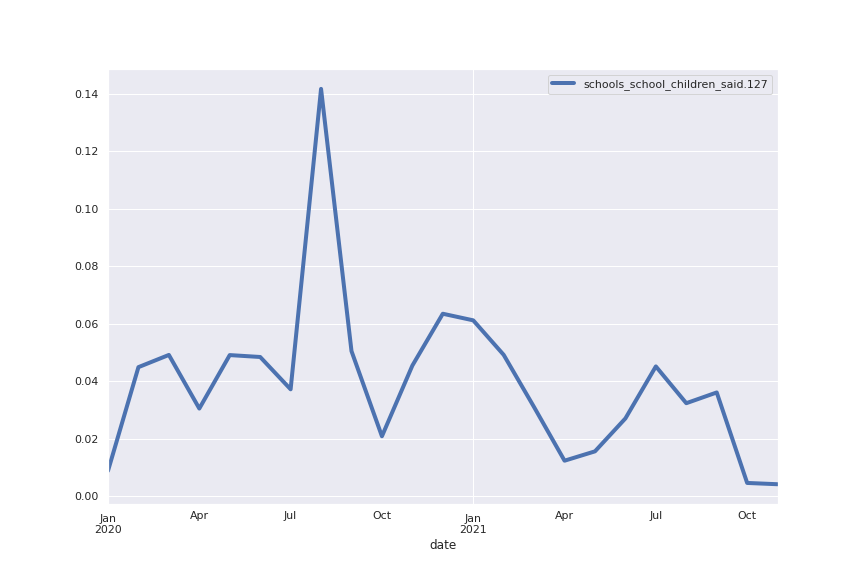
Topic 127: children

As families practise social distancing and face a new reality together, kids are still lightening the mood with funny one-liners and sweet observations.
“Senior clinicians still advise that school is the best place for children to be, and so they should continue to go to school.
Topic 32: quarantine

Be mindful of door slamming as well, especially if you’re departing for an early flight.
Freight Chaos ‘Will Trigger Disruption Like UK Has Never Experienced’.
Topic 64: tests

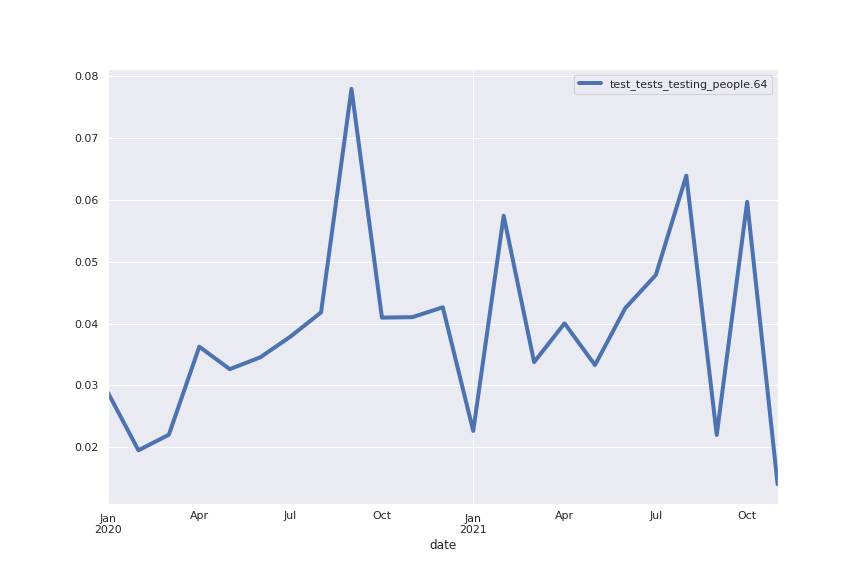
I think we need a big increase in testing,” he told the committee. “
This article explains, in a nutshell, how tests cannot be 100% accurate and therefore there is a certain margin of error in the results.
Topic 40: president
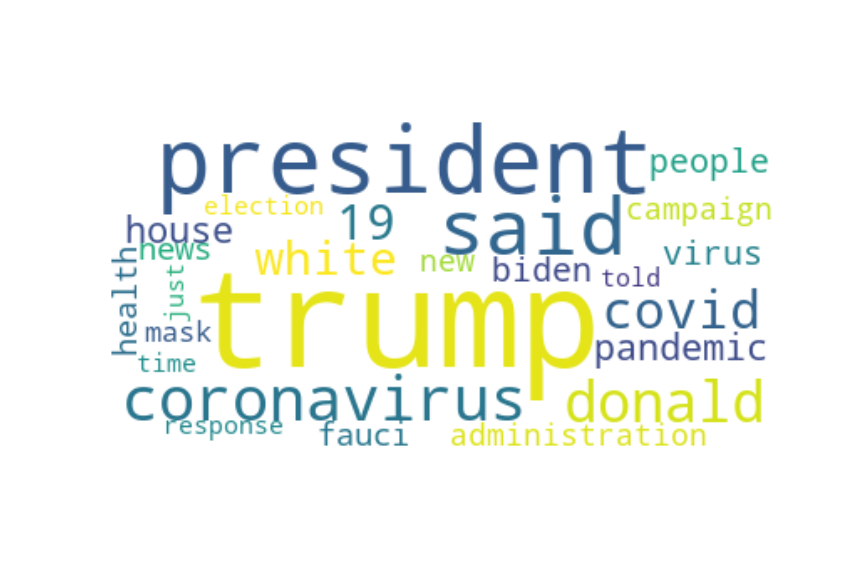
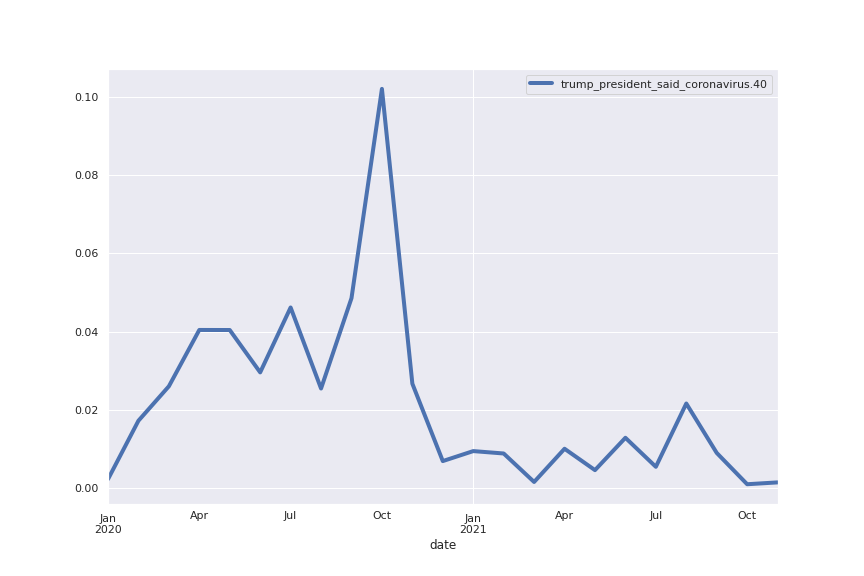
Obama addressed such concerns in his interview this week, pointing specifically to fears among communities of colour that have been disproportionately harmed by the coronavirus.
Trump raised $5 million at the event, according to CBS.
Topic 74: lockdown
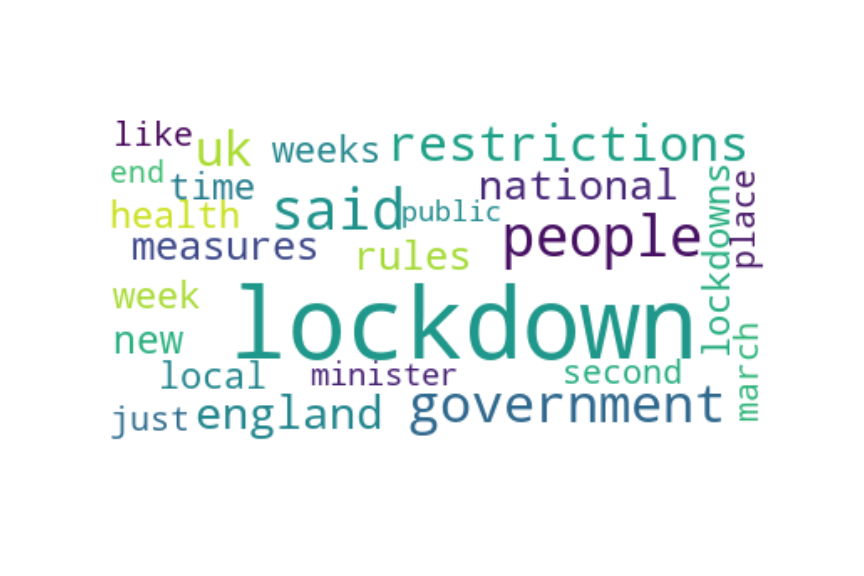
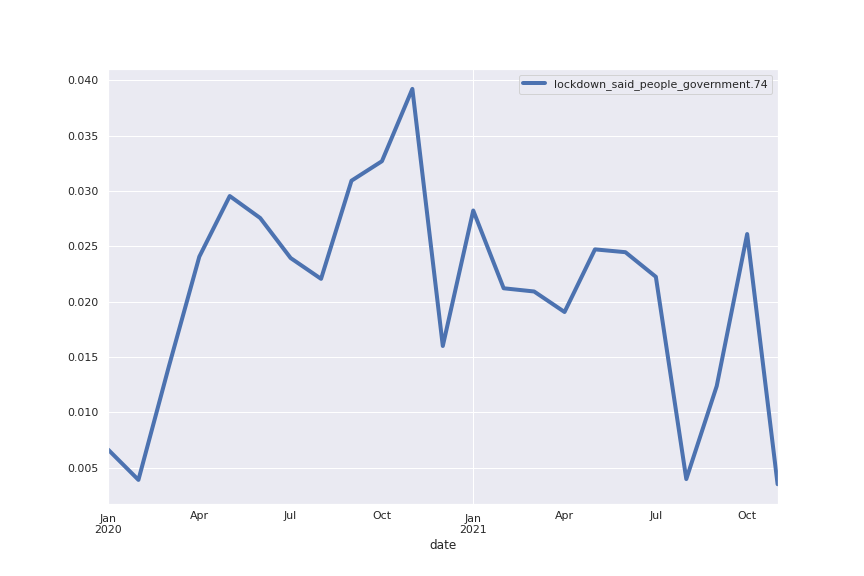
So when the enforced slowing and solitude of lockdown started, I was kind of glad of the break.
As someone who lives alone, I have to show up for myself and be my own best friend, and during a lockdown where we can’t really see our pals, this becomes all the more pertinent.
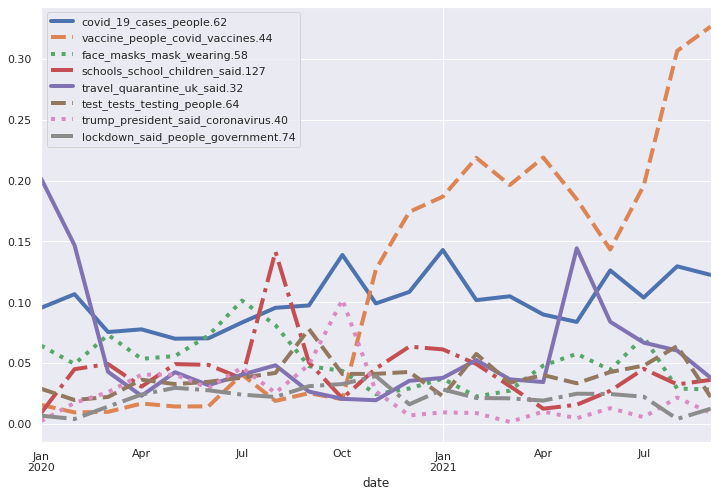
The following are the trends for the top 8 topics all represented together. The most obvious trend is the vaccination topic going from 1–2% in early 2020 to more than 30% in October 2021. This means that today, about a third of the sentences written about COVID are somehow related to vaccination.
Speaking of trends, I wanted to see if I could detect the rush for toilet paper in the first lockdown in 2020: I used the searchForWordInTopics method to search for “toilet” and sure enough found it in topic 96, albeit only in position 72. This means the word is not shown in the word cloud which for readability shows only the 25 words in the topic with highest Tfidf score. Though the topic is much smaller in size than the ones previously shown, we can clearly see a spike in March 2020 and subsequently a decreasing trend.

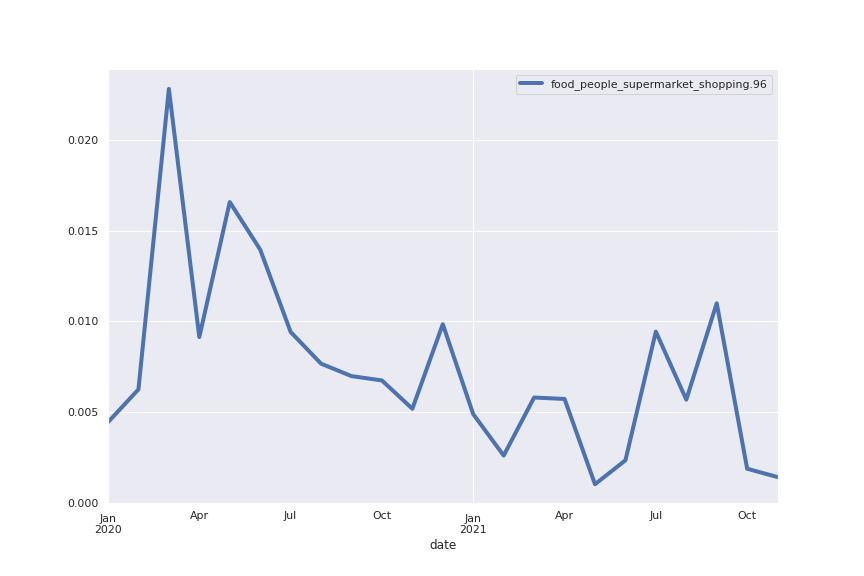
I consider heading to the grocery store to stockpile canned goods with the rest of the country, but social media tells me that lines are out the door and shelves are empty.
Besides the advantages of being able to touch, feel and try before you buy, shopping in-person can also double up as a social occasion and an opportunity to catch up with friends.
Following are several more hand-picked topics and trends. Many of these trends exhibit behaviours you would expect, though it is true that there is also a considerable amount of noise. This could also be due to the restricted data sample.

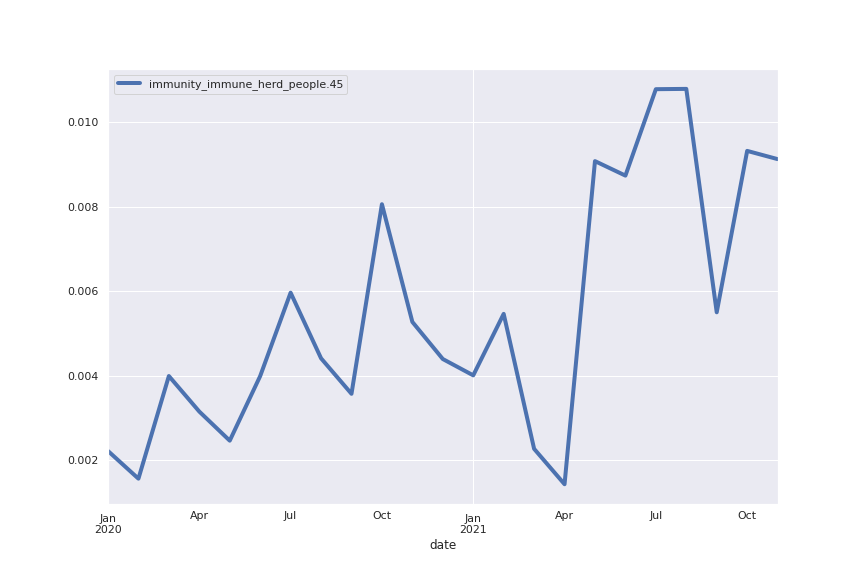

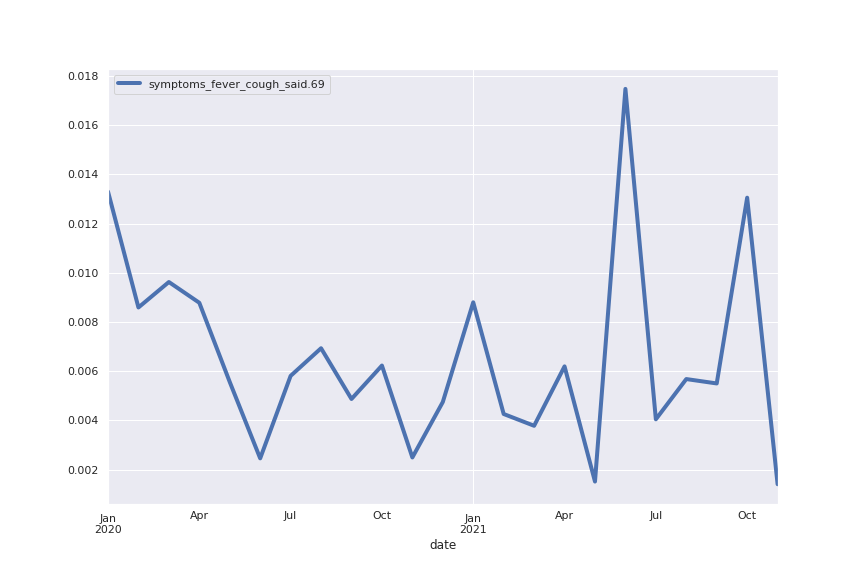

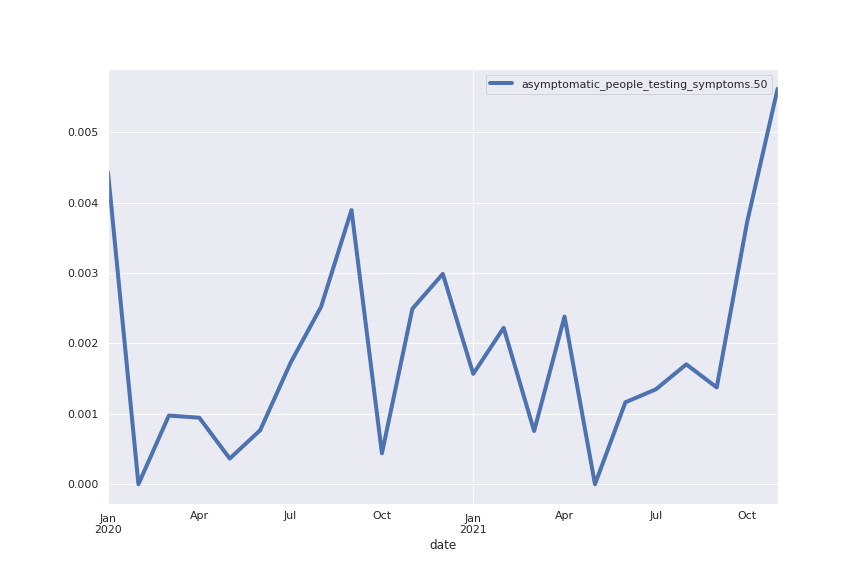

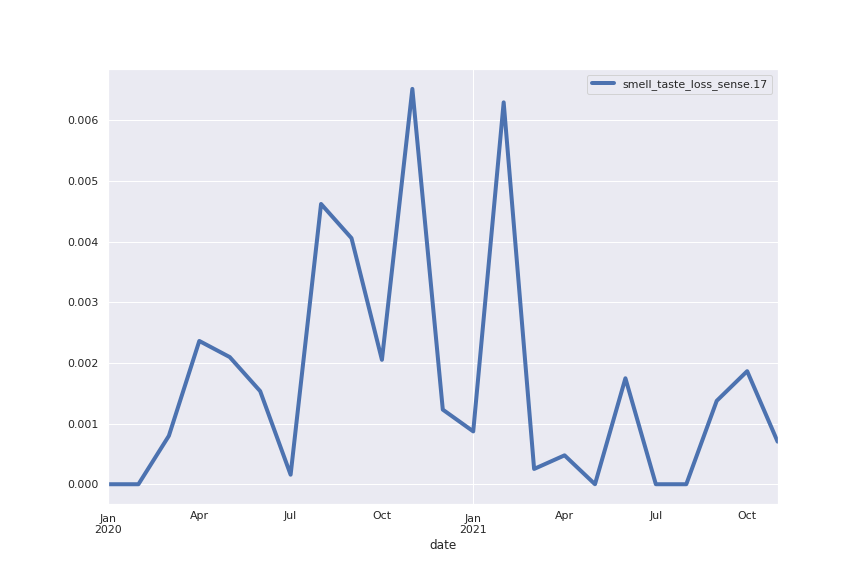

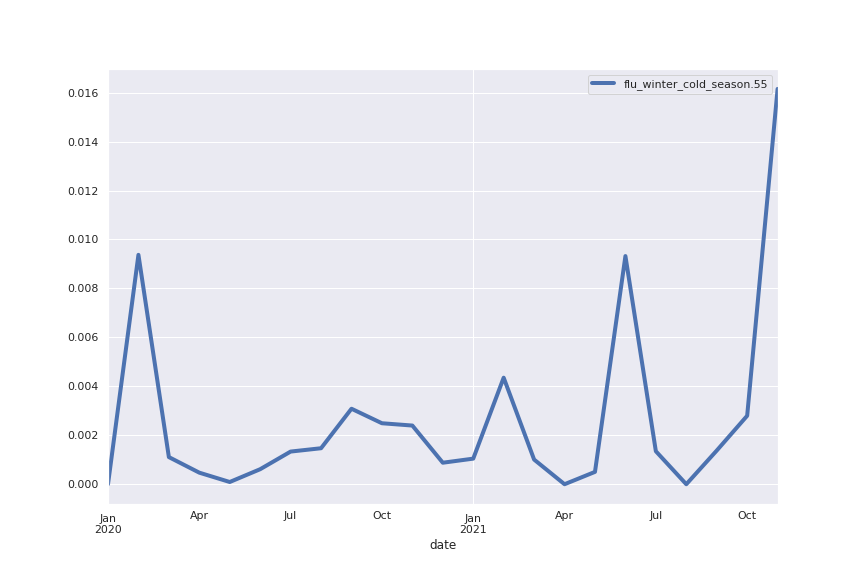

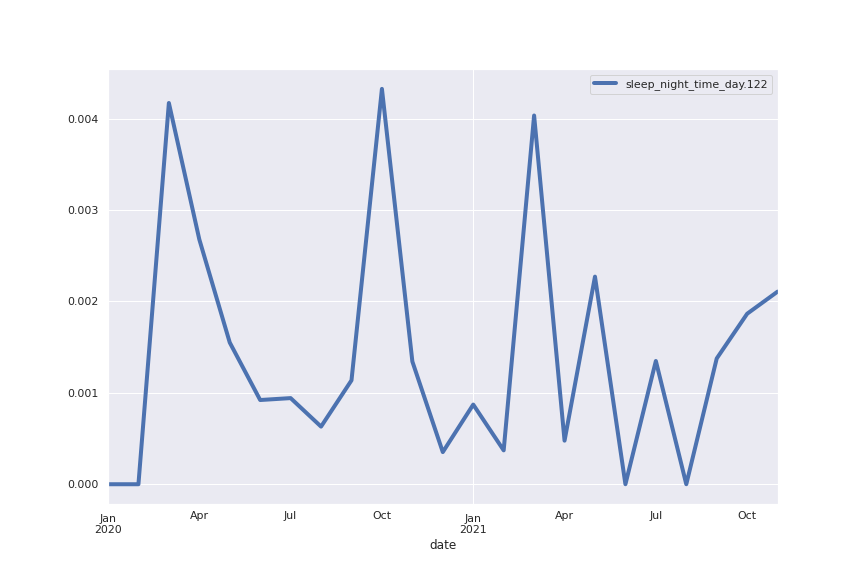

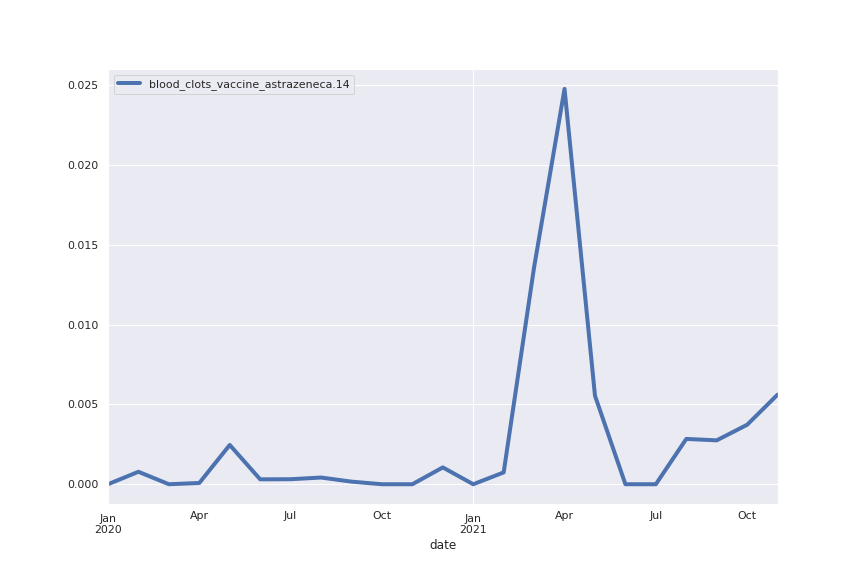
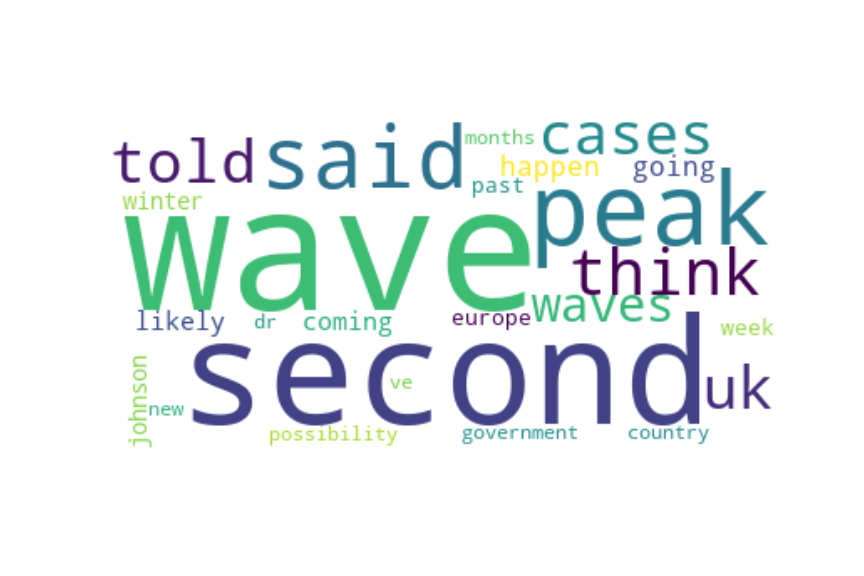
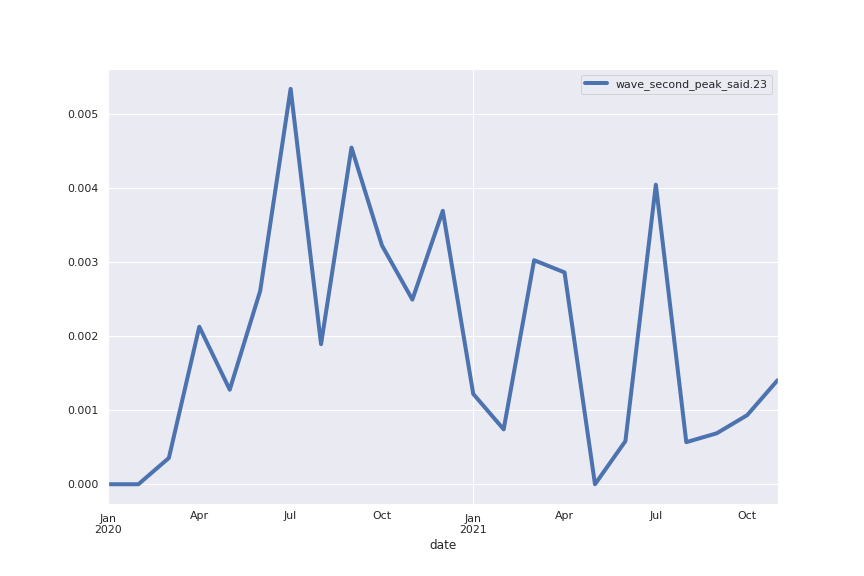

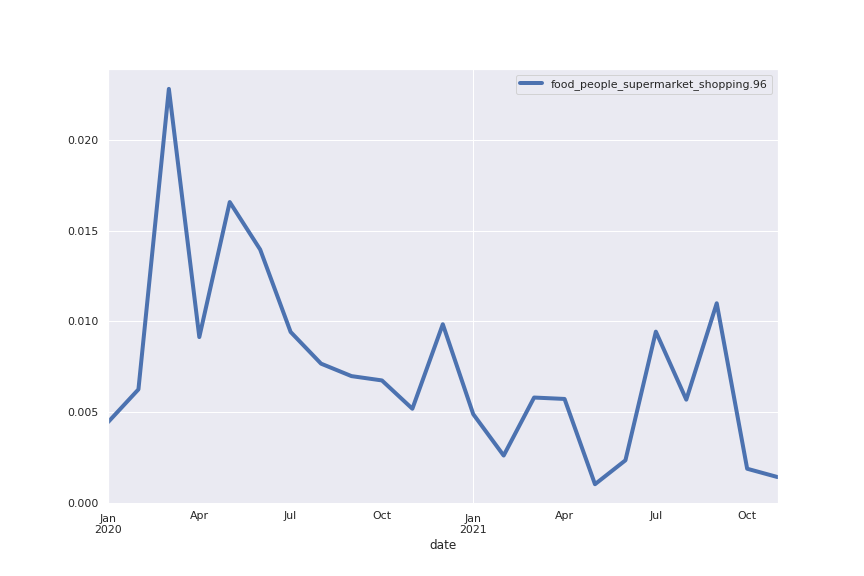

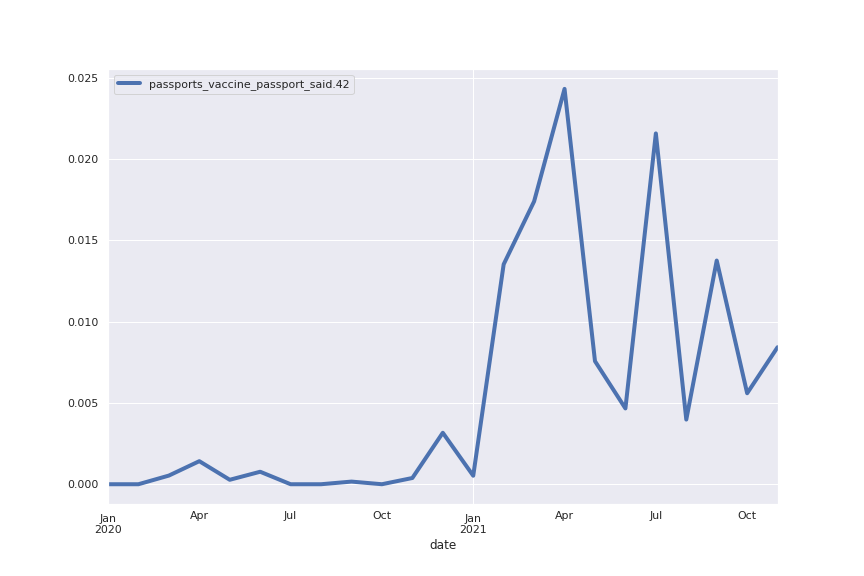

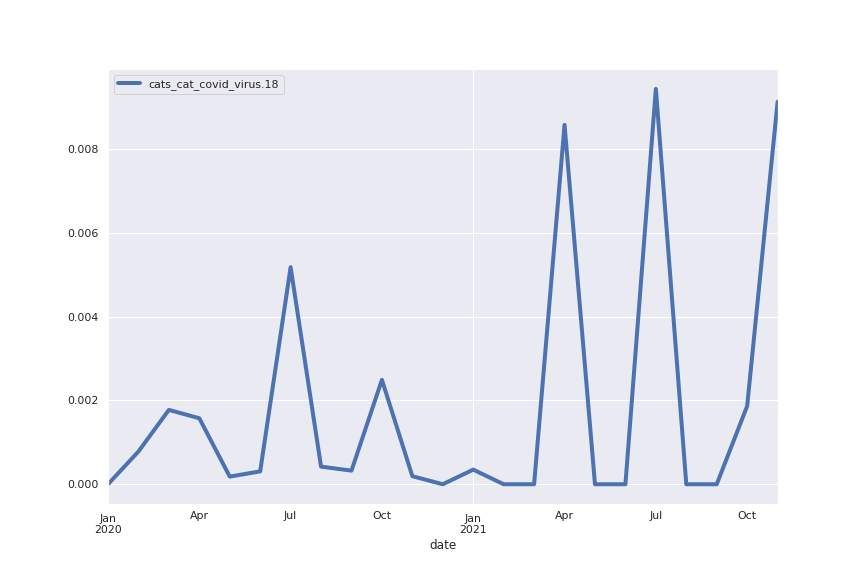

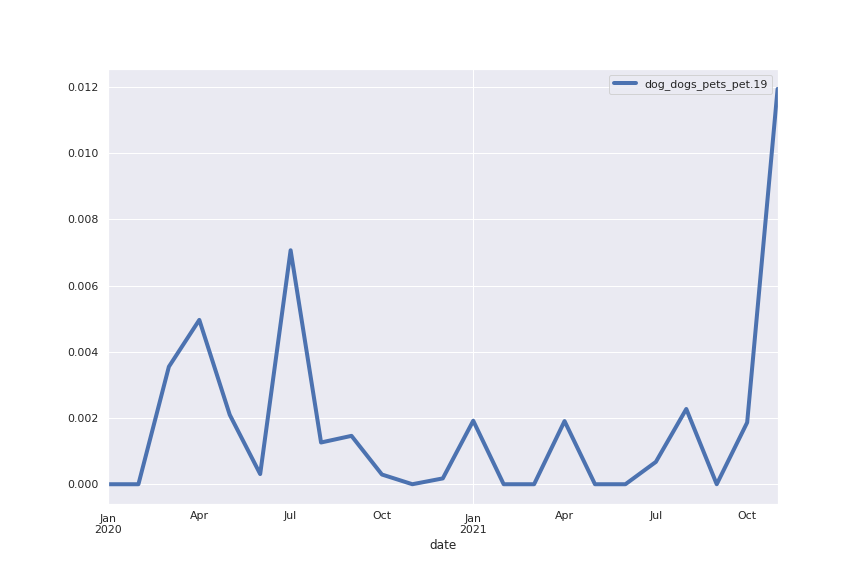

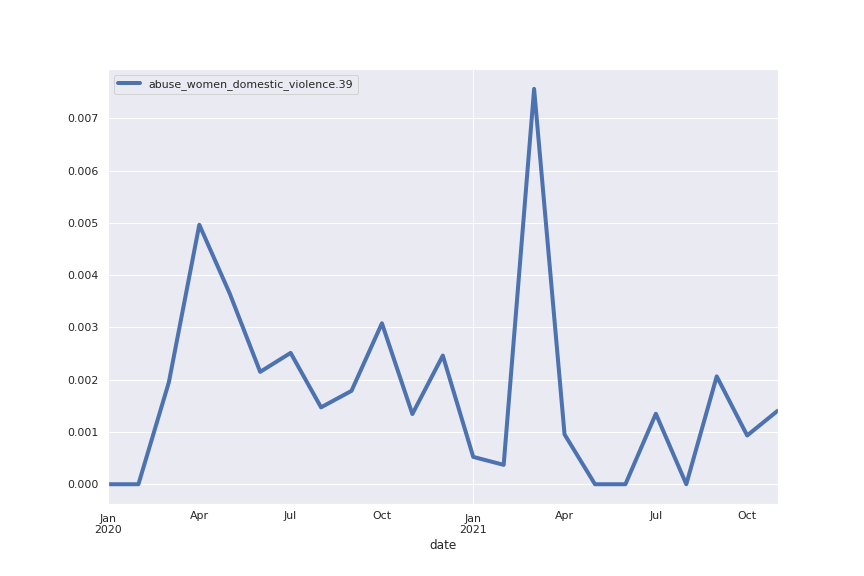

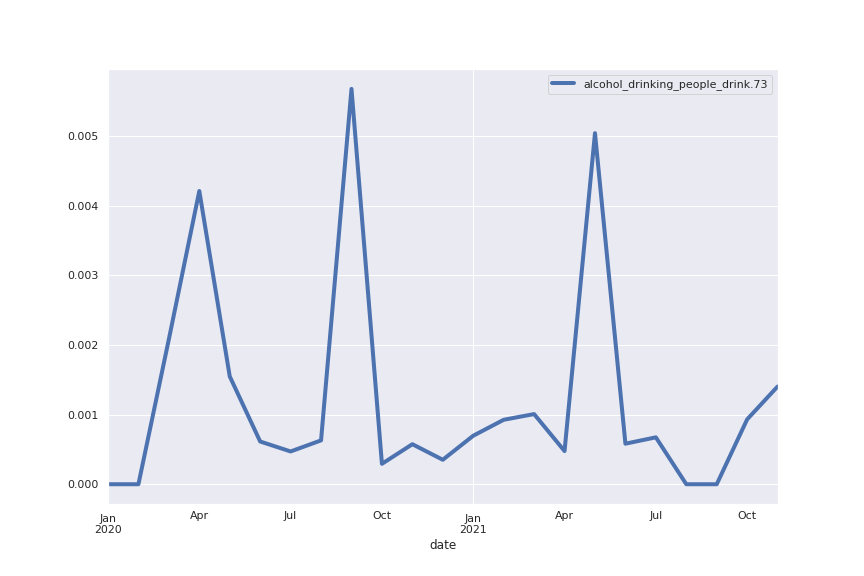

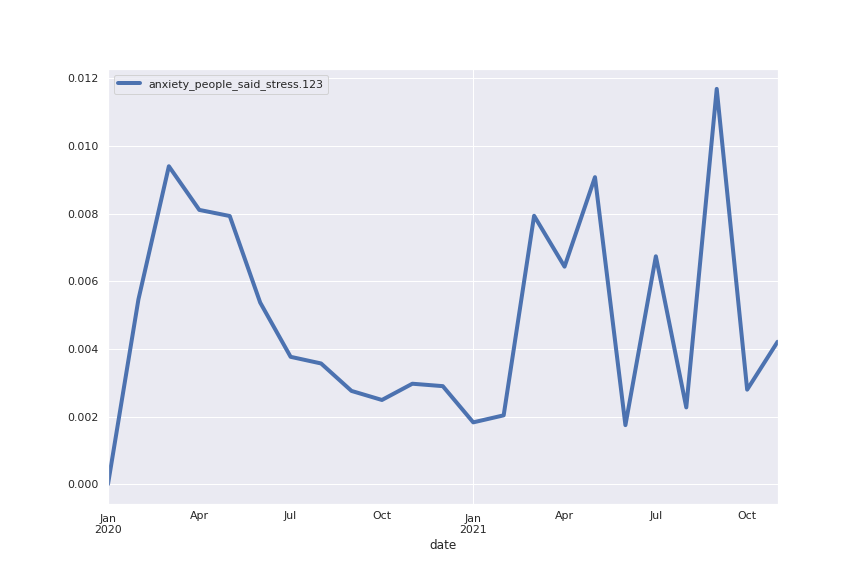

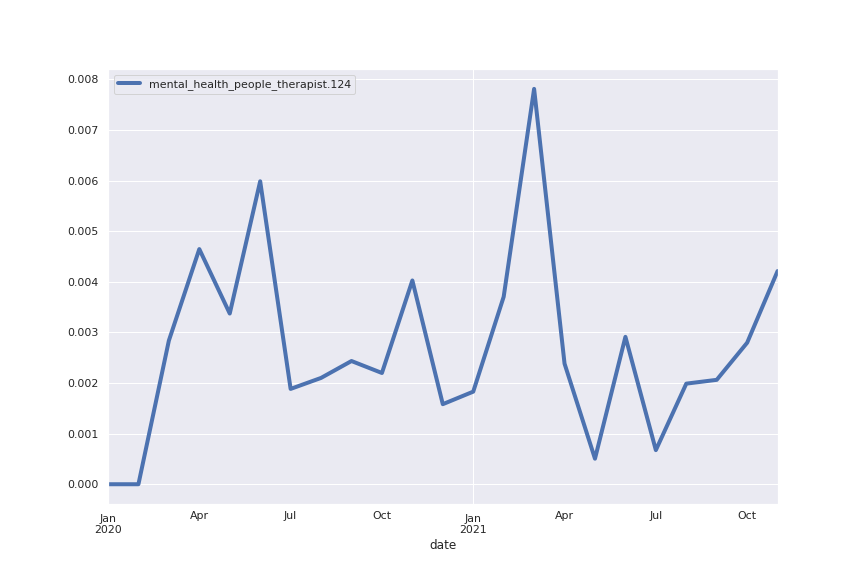
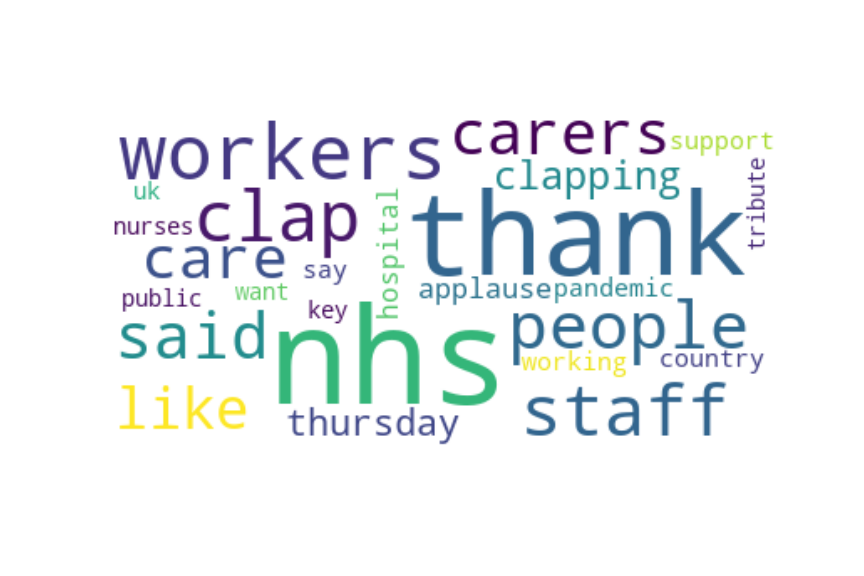
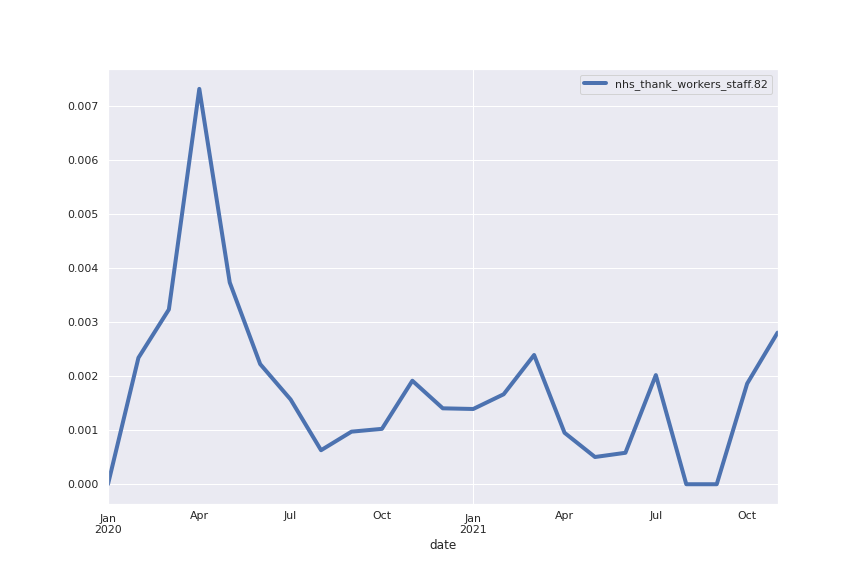

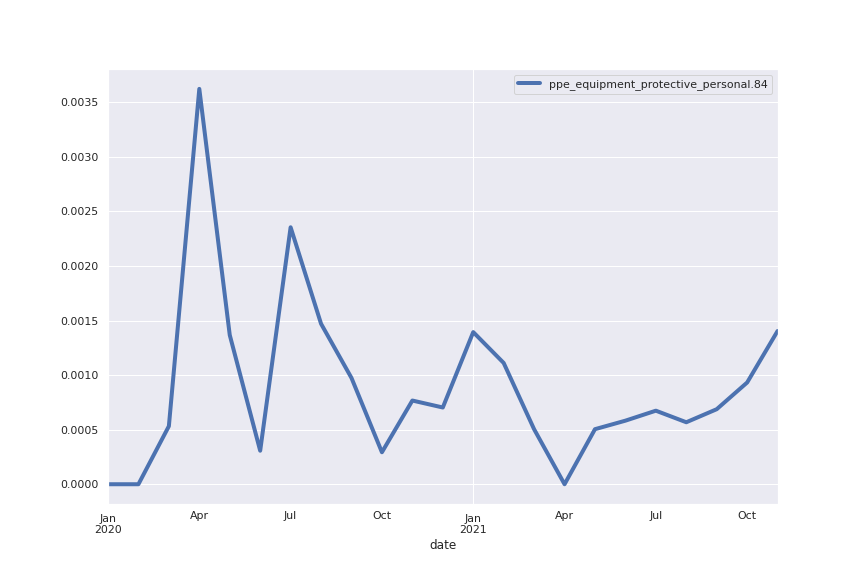

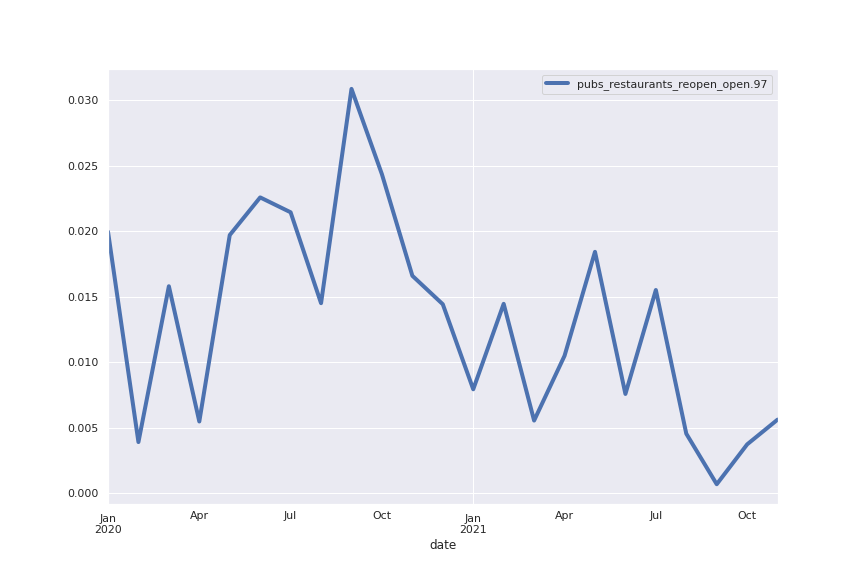
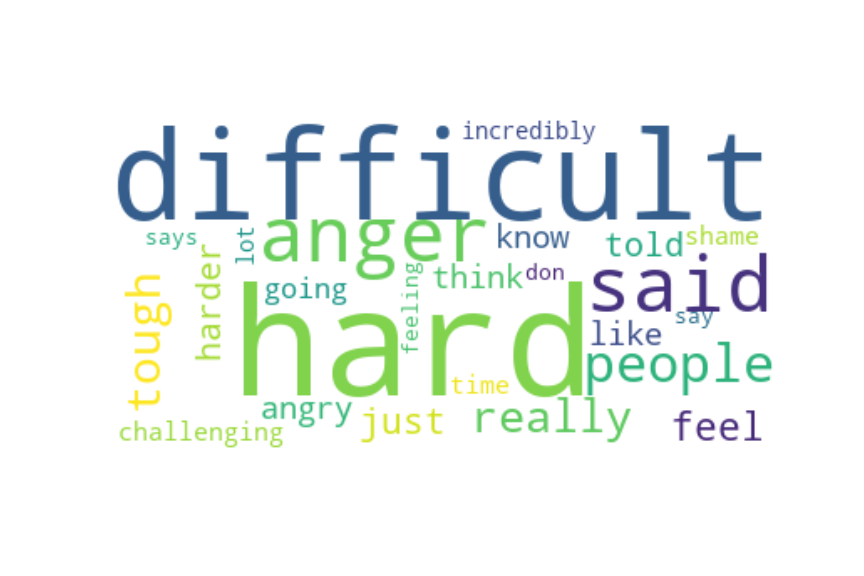
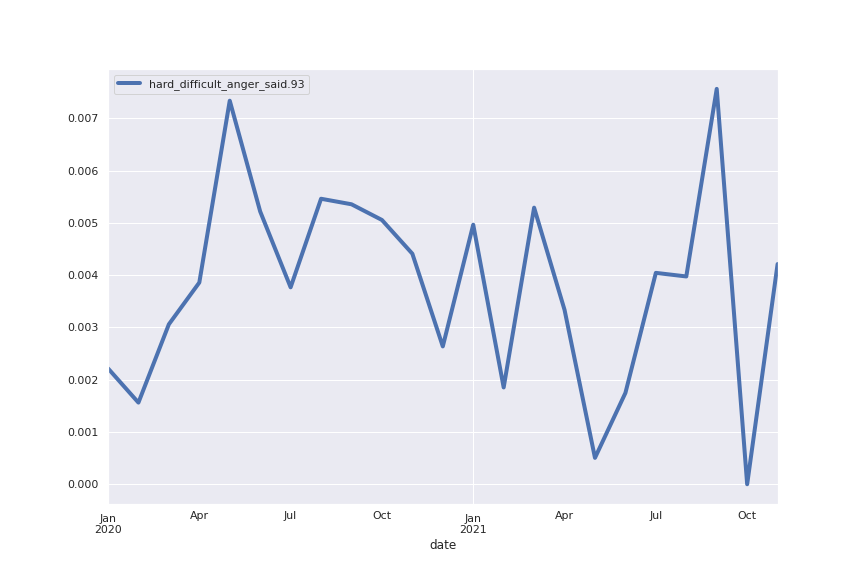

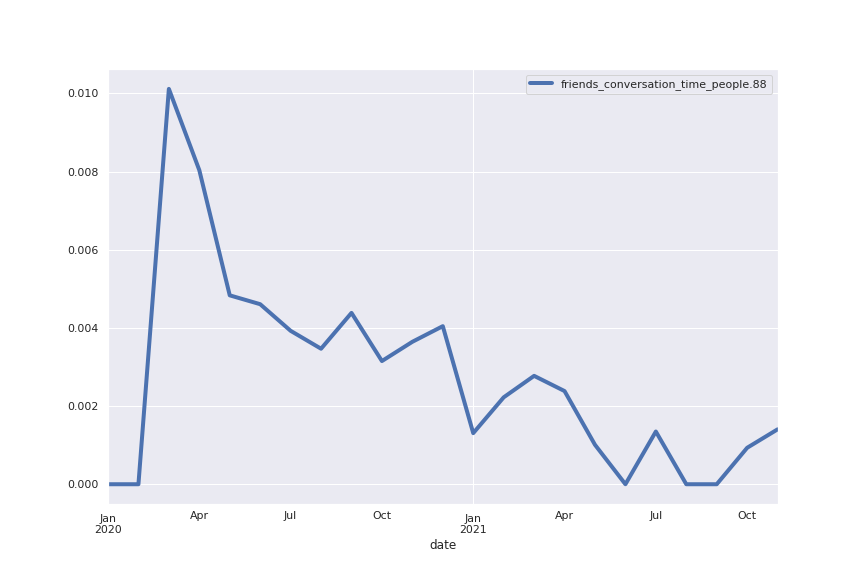
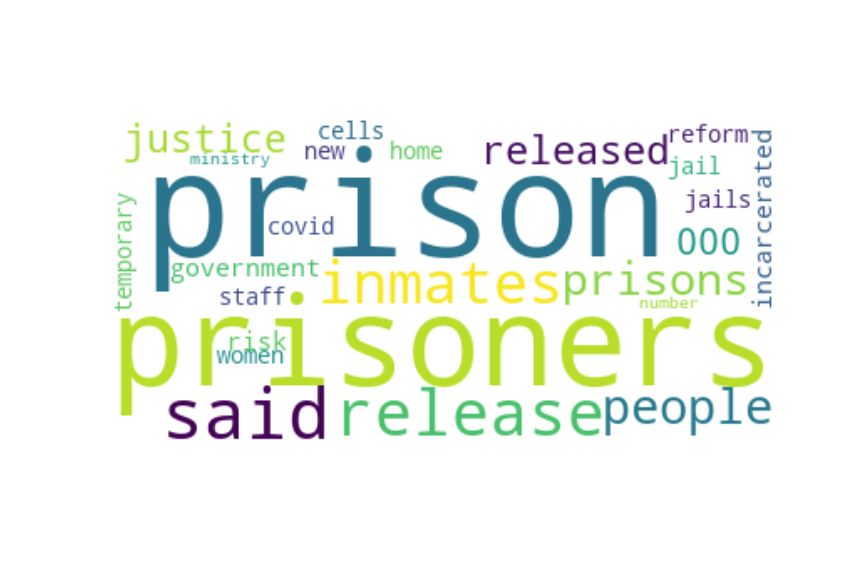
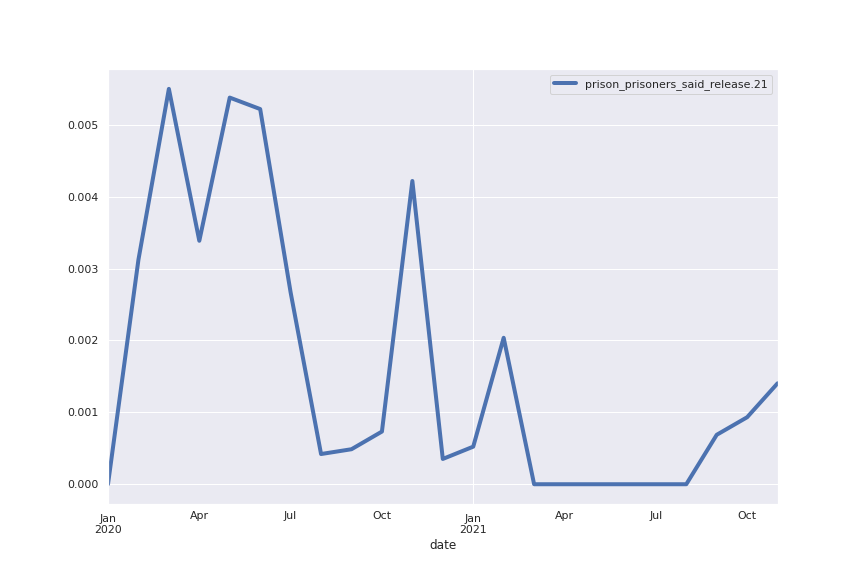

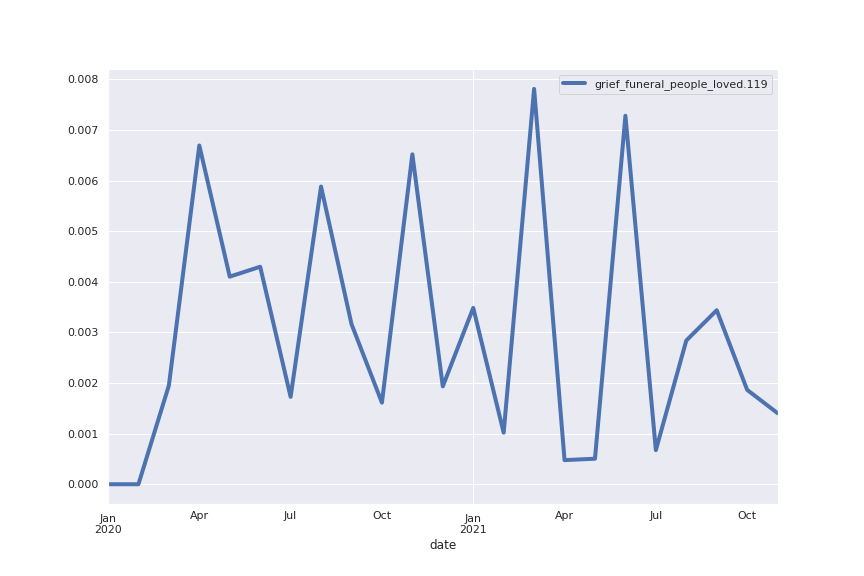

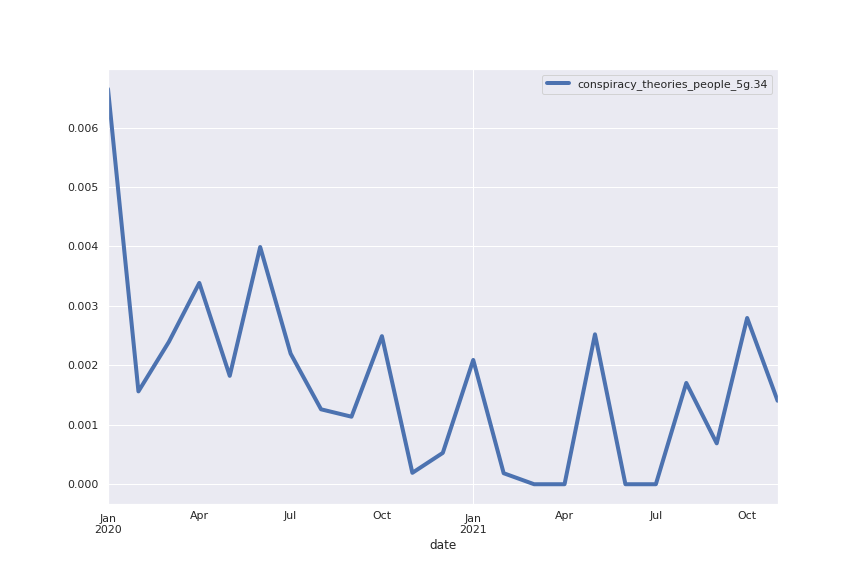

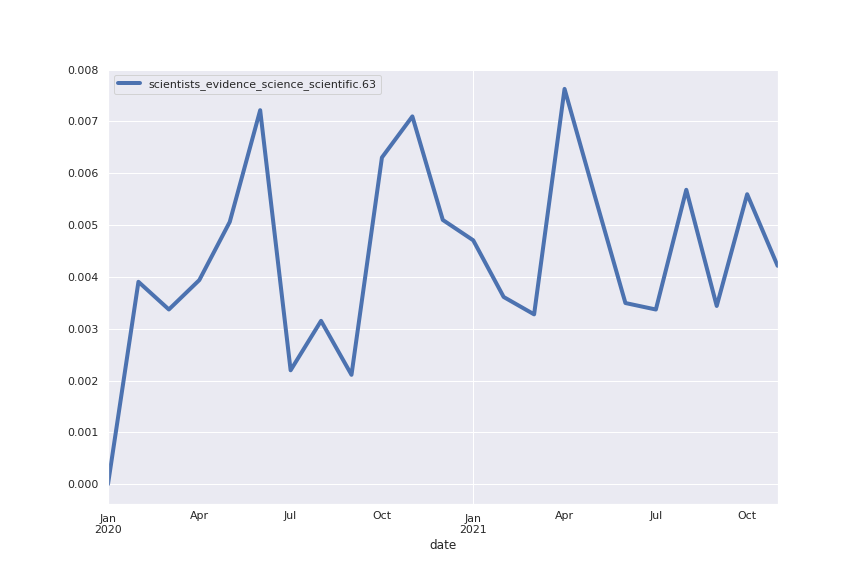
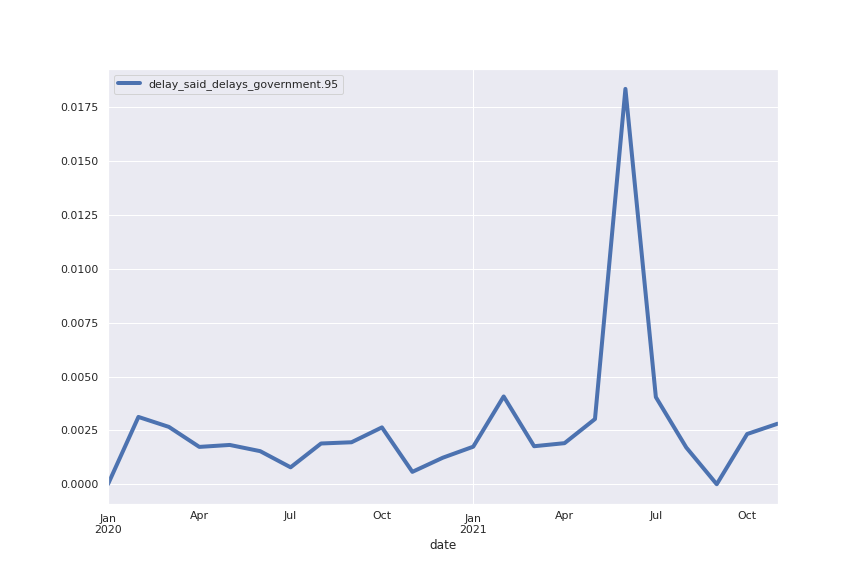

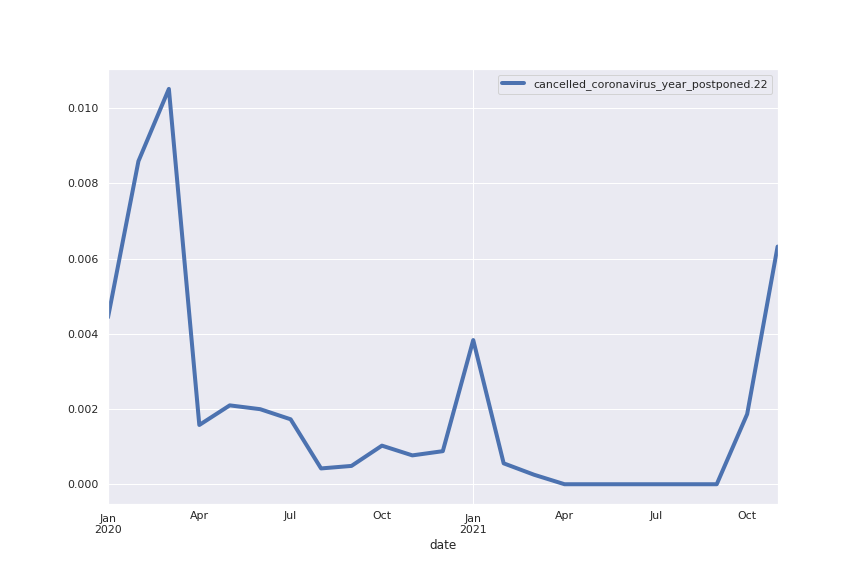
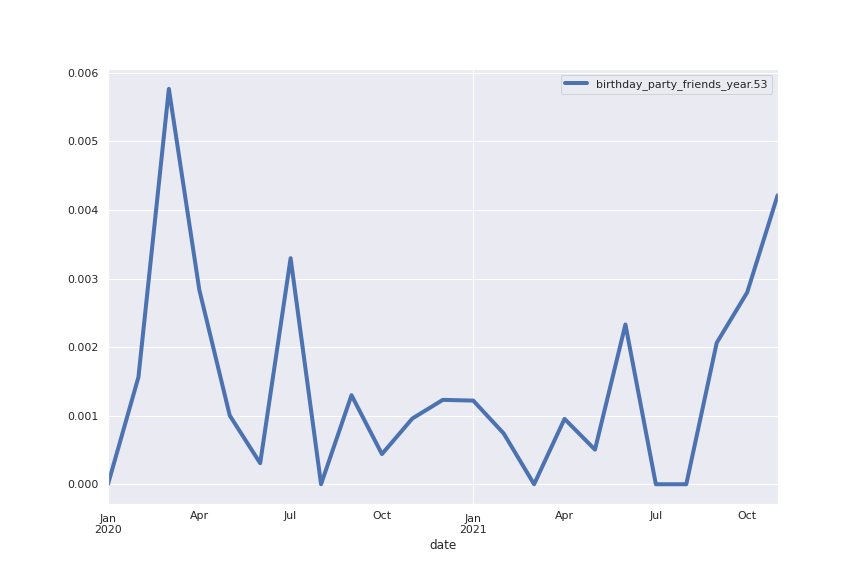

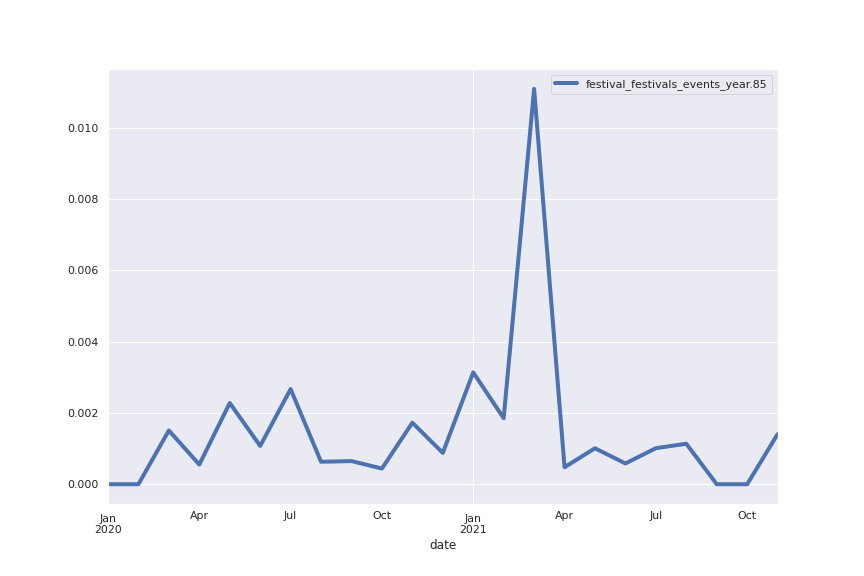

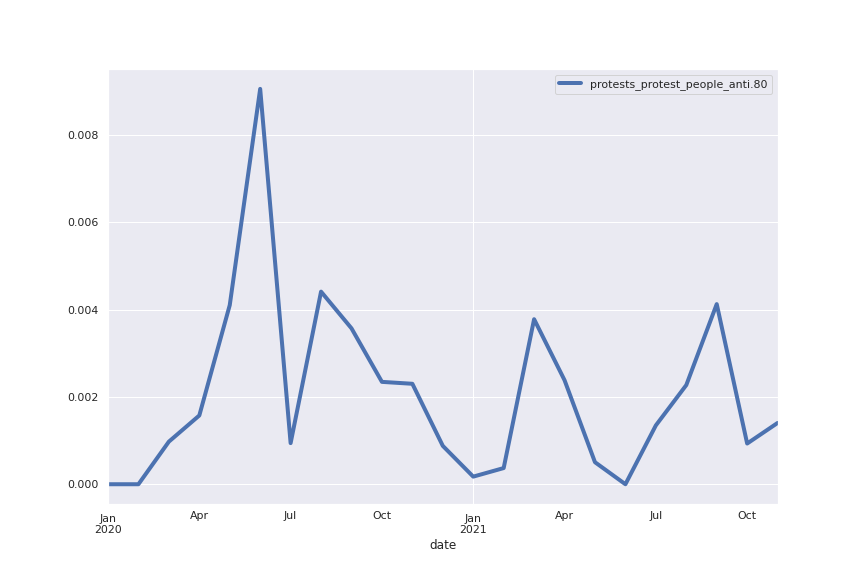

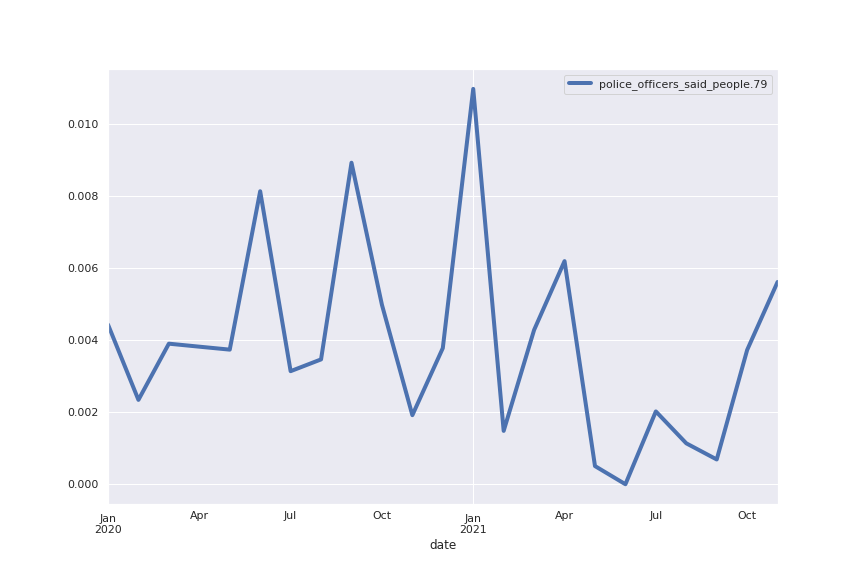

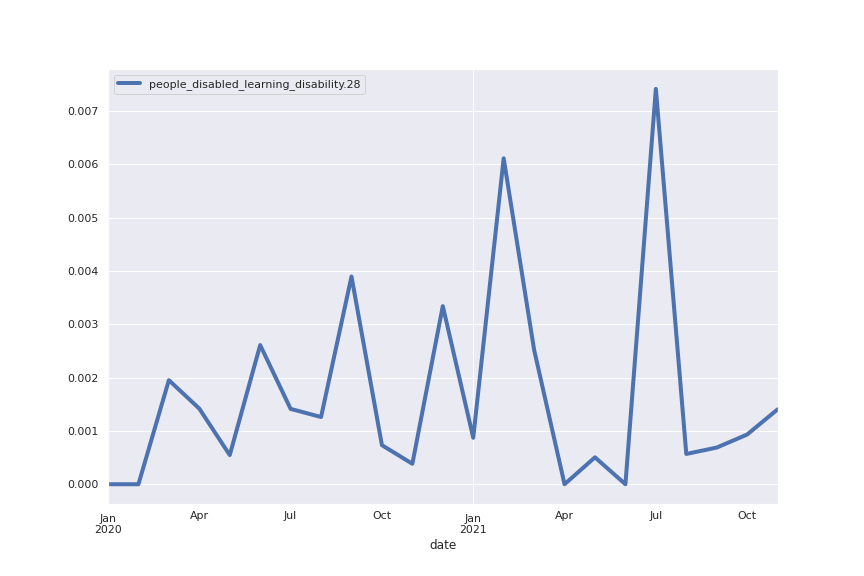
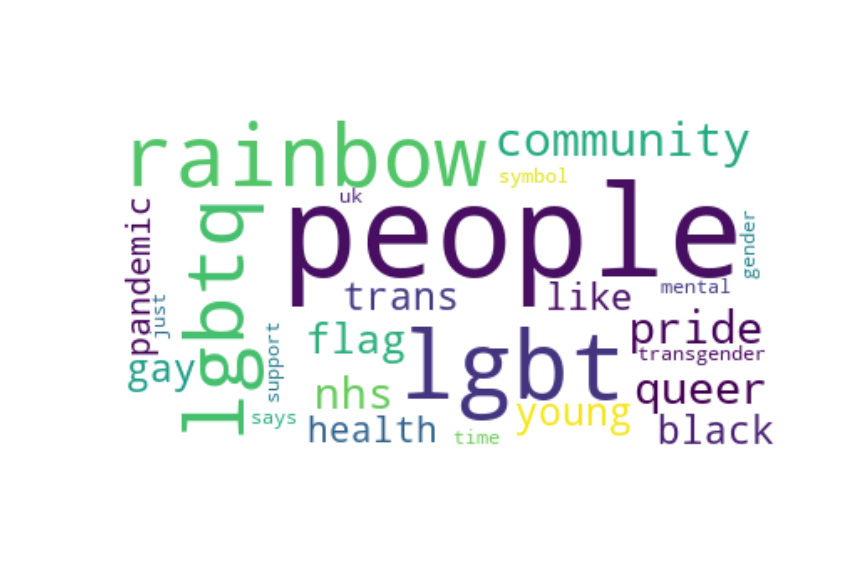
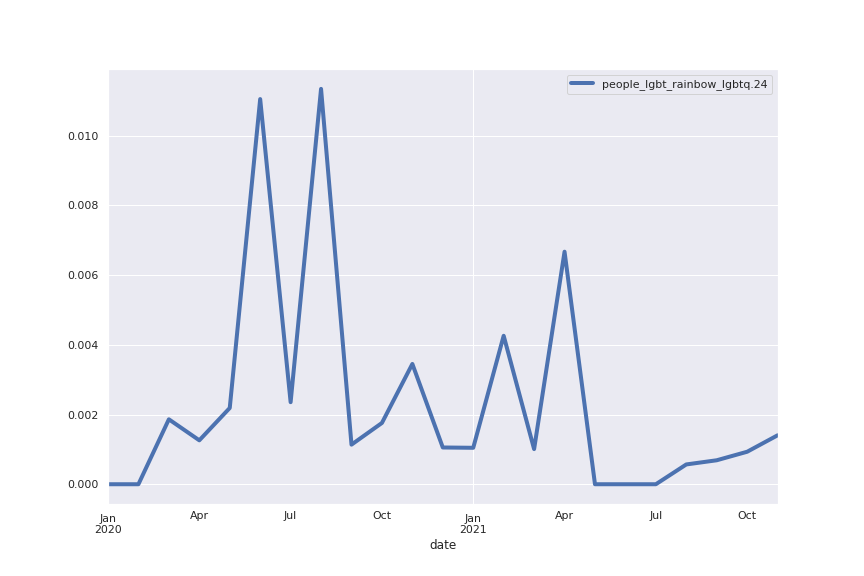

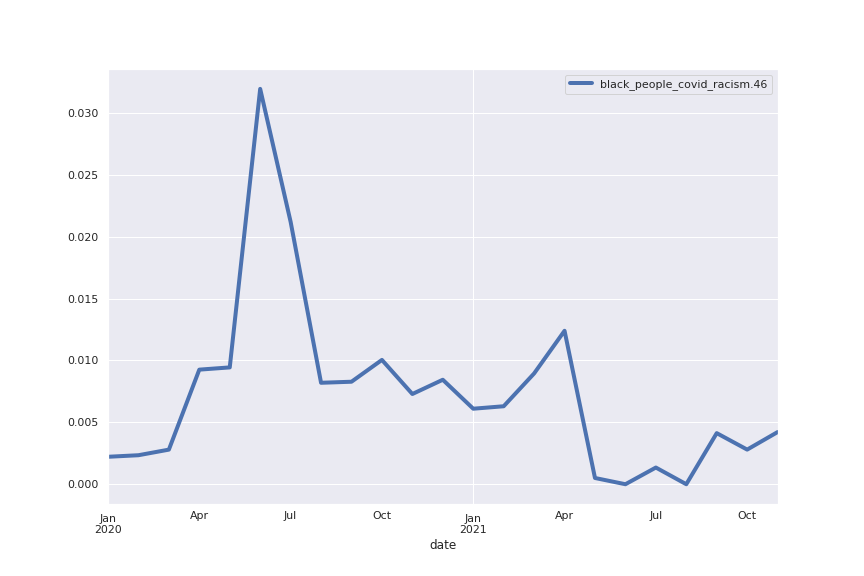

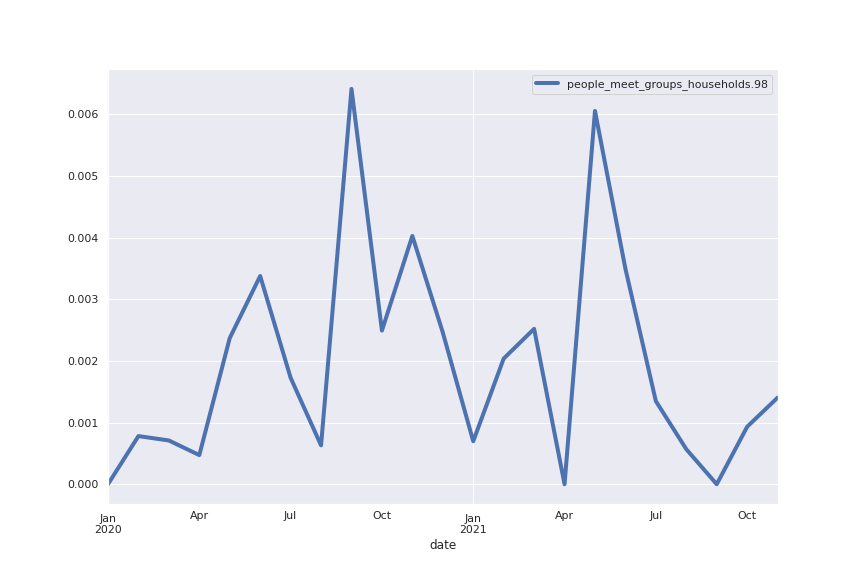

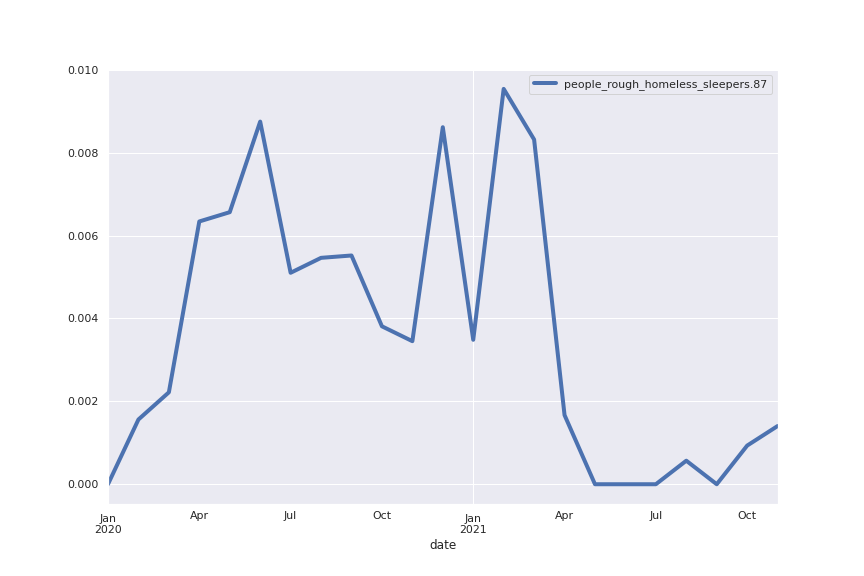
And what about LDA?
To connect to my previous post comparing transformer based methods and LDA, I also ran Gensim’s LdaModel on the same corpus. I then hard thresholded the topic distribution for each sentence, i.e. I classified each sentence as belonging exclusively to the topic it had the highest coefficient in.
Here are two of the largest topics:
So, should other pet owners be worried about their furry friends catching coronavirus?
The pandemic helped me realise that I do not thrive in an office full time.
“I am worrying, because the care job is what I want to do and I’ve been doing this for many years,” says Faye.
“As much as we want to say that individually we can set these boundaries or make these changes, it’s really difficult to do that if leadership is not on the same page,” she said.
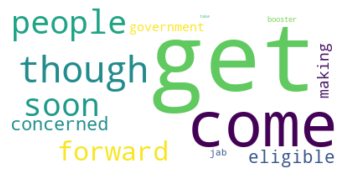
The subjective quality of the word clouds is worse, a fact that is clear from considering that the following topic has many sentences in common (shown below) with the “vaccination” topic we found with our procedures. However the only words in the word cloud related to a vaccine (jab and booster) are smaller, while very common words such as “get” and “come” are prominent.
About me
I’m a Math PhD currently working in Blockchain Technical Intelligence. I also have skills in software and data engineering, I love sports and music! Get in contact and let’s have a chat — I’m always curious about meeting new people.
References
[6] Bauckhage, Christian, and Rafet Sifa. “k‑Maxoids Clustering.” LWA. 2015.